

Data Mining
In today’s information age, we are collecting enormous amount of digital data every moment. We have tremendous number of data lying around without its valuable insight added to the organization. Data in its raw form is uninformed and does not make any sense to make it valuable for the organization. However, this raw form of data when processed makes tremendous value to make some of the invaluable decision for the organization’s growth which in future can firmly direct an organization to its higher degrees of success. It’s the matter of asking the right questions and using the right methodologies to make sense of data lying around. Data mining is this very process of selecting the required data, pre-processing of data, applying specific techniques over the processed data, then recognize various patterns to make the knowledgeable insight from the processed data.
Data Mining a Misnomer
Where data mining by its name refers to the extraction of data, however the real application behind data mining is extracting the knowledge inferred from the processing of raw data.
“It is, however, a misnomer, since mining for gold in rocks is usually called “gold mining” and not “rock mining”, thus by analogy, data mining should have been called “knowledge mining” instead.” (Osmar R. Zaine)
Structured, Unstructured, Semi-Structured Data
There are different ways for the presence of data to be in the data warehouse, Structured, Semi-Structured (World Wide Web) and Unstructured data. Structured data is followed by keeping the integrity of data and the relationship between two different data. This is usually maintained on industry leading traditional relational database systems (RDBMS) like MySQL, SQL Server. There is also another form of data – unstructured data, which is very popular nowadays for its quick implementation and dumping the data as we go and figure out the relation and integrity of data as we go along with our progress of the achievable development target. We save big chunk of development time on figuring out the relation and integrity between the data while on the other hand losing the time to clean up and arrange the same data later. For unstructured data, primarily we use MongoDB, but any text-based flat files are also feasible. Data can be mined for all structured, unstructured, or semi-structured data.
Some of the key data mining techniques for structured data are as follows:
Classification: Classification is a data mining technique where data is categorized / classified into different categories which helps to understand more on the specification of individual data. In this technique we know the labels before categorizing.
Regression: Regression is a technique to understand the likelihood of dependent variable, given the impact of another independent variable over the dependent variable.
Clustering: Clustering technique helps us to understand label unsupervised data into different clusters which are like each other and provide meaningful insights to them. This technique is based on unsupervised data as we don’t know anything about the clusters and how the clusters will be grouped into one another.
Association Rules: It is the data mining technique to determine the pattern, association, and correlation between the variables in the data set. For example, if the customer buys, bread they are more likely to buy an egg which is associated with bread and marketing agendas can be ran based on these associations.
Prediction: Prediction is one of the most valuable data mining techniques to predict the future outcome based on the historical data and its trends. We can use this technique to recognize existing data and predict the possible outcome of data in the future.
Clustering
Clustering is one of the most widely used unsupervised data mining techniques which divides the data points to its similar groups together (Intra-cluster) and away from the data points (Inter-cluster) which are different from each other. For example: If we have development index of every country in the world, clustering technique will help us to find similarities between different countries and group them together while also separating the group of countries from each other (clusters) to provide us the different clusters in which different countries belong to.
The goal of clustering is to determine as much as similarity between (intra-cluster) and as much as separation among (inter-clusters).
Hierarchical Clustering Algorithm
In Hierarchical Clustering we have two different approaches to group the clusters:
- Agglomerative Clustering
- Divisive Clustering
Hierarchical clustering is graphically represented by tree-like diagram called _ dendrogram _, which displays both cluster and sub-clusters.
 Source: Wikipedia
Source: Wikipedia
Agglomerative Clustering Algorithm
In Agglomerative Clustering, each data point is considered as a granular single cluster and then gradually, after each iteration moves its way up towards until one single group of similar clusters is formed. This algorithm is also known as bottom-up approach.
Divisive Clustering Algorithm
As the name suggests, in this algorithm initially we consider all the data points as one big single cluster and there is one single cluster on which after each iteration, data points are separated from the cluster which are not similar and gradually division separates multiple n number of clusters, hence it is named as Divisive Clustering. This algorithm is also known as top-down approach.
 Source: Wikipedia
Source: Wikipedia
Agglomerative Hierarchical Clustering Algorithm Linkages
This is the very basis by which the clusters are formed. All the approach to agglomerative clustering starts from one granular individual single cluster which with every iteration merge until one single cluster remains by calculating the similarity between two different clusters. There are different approaches to calculate the similarity between two clusters:
- MIN (Single Linkage)
- MAX (Complete Linkage)
- Group Average (Average Linkage)
- Distance Between Centroids (Centroid Linkage)
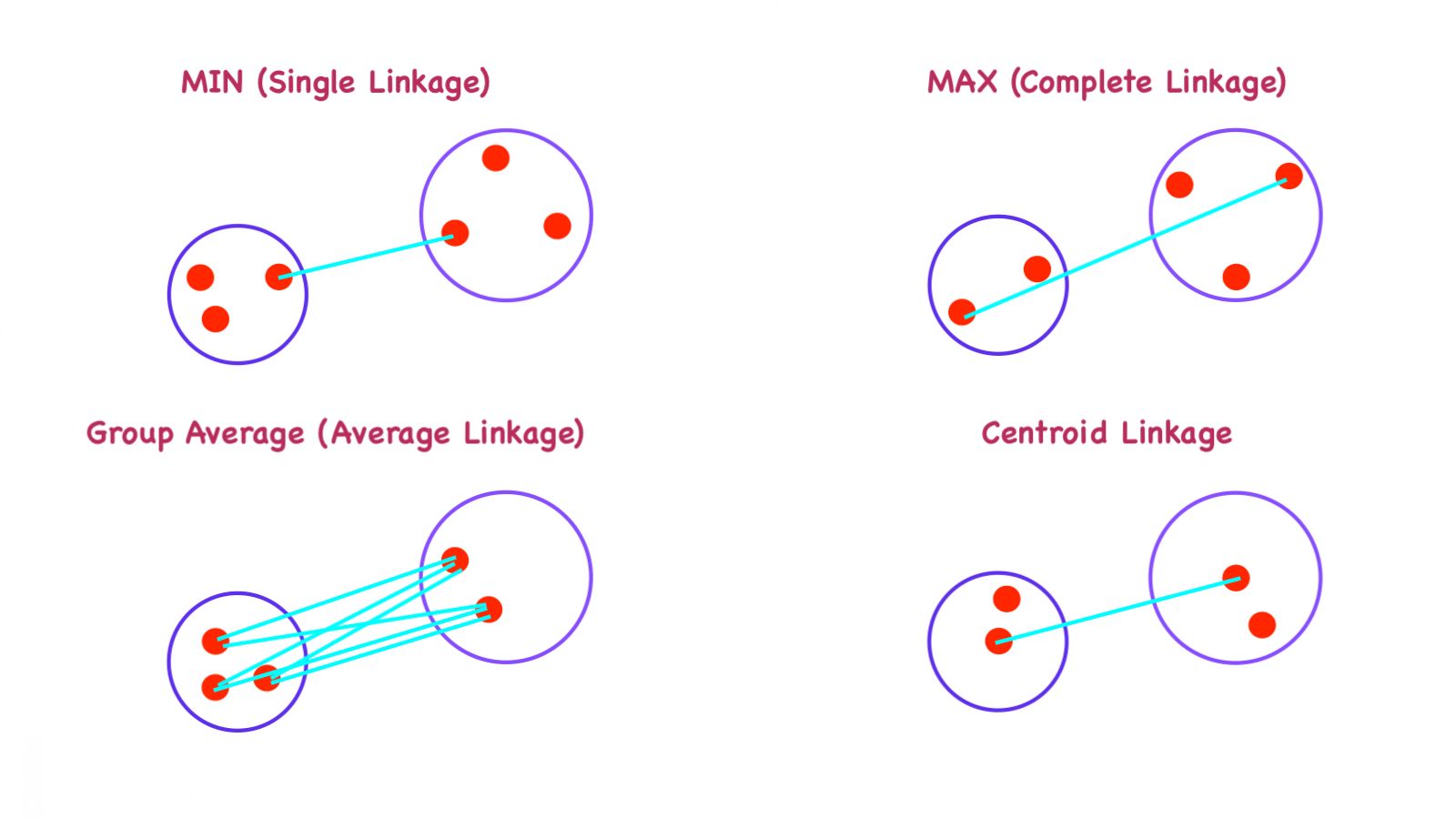
As represented in the figure above, 1st figure (top-left) represents the MIN (Single Linkage) where two points that are in two different clusters are taken and their proximity distance is calculated and registered in proximity matrix until one cluster remains.
Alternatively, MAX is represented on the 2nd figure (top-right) where two points are farthest away from each other in two different clusters and their proximity is calculated until one cluster remains. Similarly, 3rd figure (bottom-left) is representing Group Average and 4th figure is representing Distance between Centroids of two clusters.
Limitation of Hierarchical Clustering
One of the major limitations of Hierarchical Clustering is that it is difficult to apply on larger data sets given its algorithm which performs n iterations over every data points. This induces both time and space complexity which becomes the huge barrier for this algorithm to apply on bigger data sets.
REFERENCES:
Zaine, Osmar R., “What are Data Mining and Knowledge Discovery?” (Chapter I: Introduction to Data Mining) https://webdocs.cs.ualberta.ca/~zaiane/courses/cmput690/notes/Chapter1/
Patlolla, Chaitanya R. (2018), “Understanding the concept of Hierarchical clustering Technique”
Joseph, Rohan (2018), “Learn with an example : Hierarchical Clustering”, https://medium.com/@rohanjoseph_91119/learn-with-an-example-hierarchical-clustering-873b5b50890c
Bonthu, Harika (2021), “Single-Link Hierarchical Clustering Clearly Explained!”, https://www.analyticsvidhya.com/blog/2021/06/single-link-hierarchical-clustering-clearly-explained/
https://cs.wmich.edu/alfuqaha/summer14/cs6530/lectures/ClusteringAnalysis.pdf